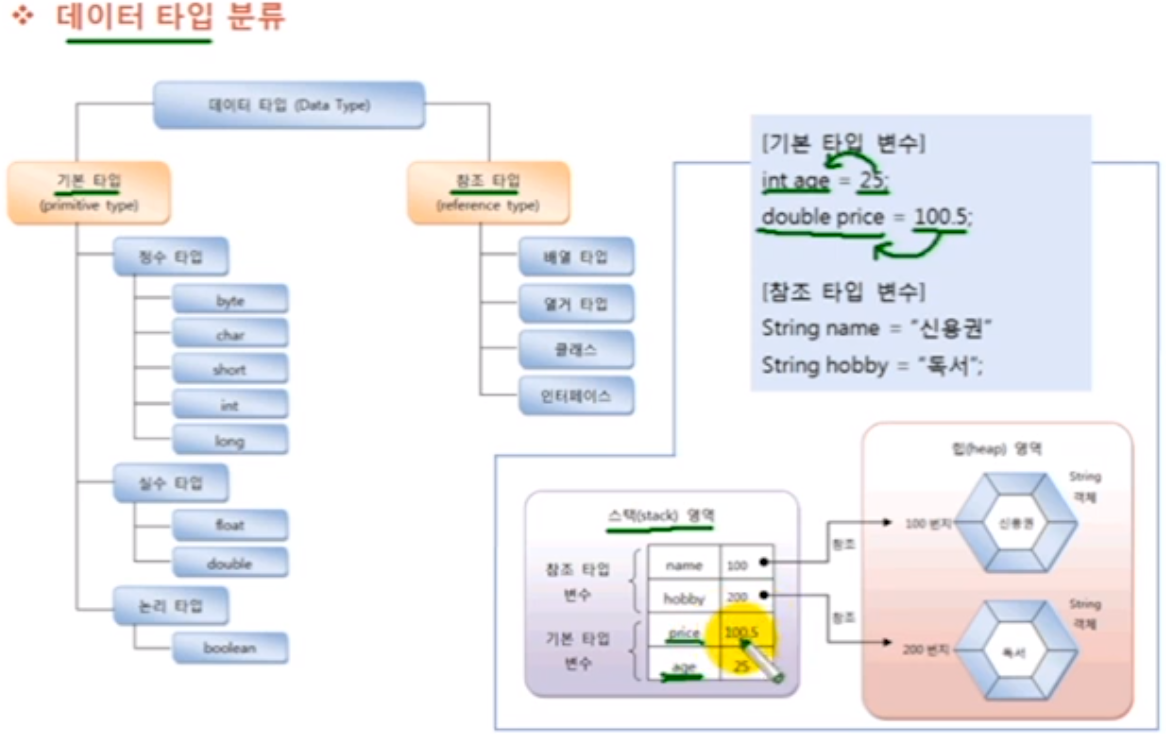
변수라면 일단 스택영역에 생성되지만
자바의 데이터 타입중에서
기본형은
자바랭귀지에서 지원해주는 primitive타입을 말하며, 스택영역에 존재하고 있는 변수가 직접 값을 가진다.
예) byte, char, short, int, long, float, double, boolean
참조형은
배열, 열거형, 클래스, 인터페이스, String 처럼 스택영역에 존재하는 변수가 직접 값을 가지지 않고 힙영역에 존재하는 객체의 메모리 address를 가지고 있는 타입을 의미한다.
JVM이 OS에서 할당받은 메모리 영역(Runtime Data Area)은 크게 3가지로 구분된다.

1. 메소드영역(=클래스영역)
2. 힙 영역
3. JVM스택(콜 스택)
참조: https://codedragon.tistory.com/5297
https://www.youtube.com/watch?v=vCKJacN_C3c&list=PLVsNizTWUw7FPokuK8Cmlt72DQEt7hKZu&index=31

기본형과 참조형 값의 비교(==,equals)
우선 ==는 자바랭귀지에서 하나의 값에 대해서 같은지를 판단하는 연산자이고
equals()는 모든클래스의 최상위 클래스인 Object가 가진 메소드이다.
기본형의 경우에는 ==로 항상 바로 비교가 가능하다.
하지만 참조형의 경우에는 ==로 비교하려고 하면 기본적으로
'참조변수가 알고있는 메모리 번지수가 같은지?'로 비교하기 때문에
문제가 될 수 있다. 재정의 하지 않은 equals()는 ==연산자와 완전히 똑같이 메모리 주소를 기준으로 비교하는 기능을 하므로 쓸모가 없다.
제대로 사용하려면 equals()를 오버라이딩 해야한다.
equals()의 등장배경에는 '논리적 동등성'과 밀접한 관계가 있다.
논리적 동등이란 '같은 객체이건 다른 객체이건 상관없이 객체가 저장하고 있는 특정 데이터가 동일하면 같은 것으로 보려는 접근방법이다'
예를 들어 11학번 졸업자들 가운데 취업자들을 서로 매칭하는 애플리케이션을 구현하려 할 때, name필드는 달라도 학번이 11학번이고 취업에 관한 필드가 true기만 하면 해당 졸업자들 간에 같다고 평가 하도록 만드는 경우가 있겠다.
따라서 equals()는 직접 사용하기 보다는 항상 재정의를 통해서 논리적 동등성으로 비교하는 목적으로 사용된다.
Object클래스가 가지는 메소드 중에 hashCode()
객체간 논리적 동등성 판단에 중요.

String의 논리적 동등성
문자열이 같을 경우 동등 객체가 될 수 있도록
hashCode()와 equals()메소드가 기본적으로 재정의 되어있다.
자바의 자료구조 구현체들
list컬렉션 (arraylist, linkedlist, vector)
중복해서 객체 저장 가능(실제로는 객체의 번지를 저장가능 하다고 해야 함)
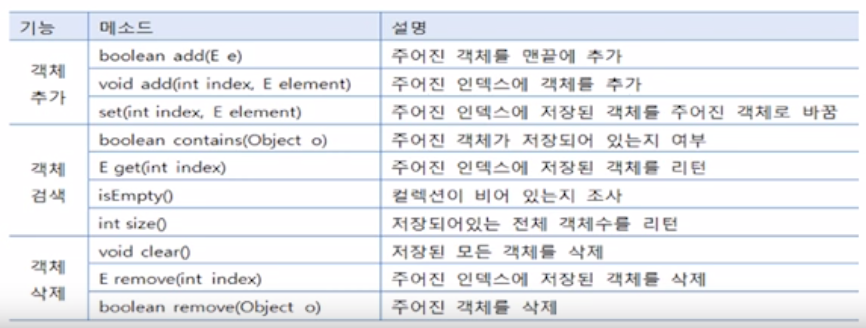
arraylist
동기화처리가 되지 않기 때문에 빠르게 처리 가능
초기 저장용량을 생략하면 기본적으로 10의 저장용량을 갖는다. 기본적으로 데이터를 추가할 때는 인덱스 순으로 자동 저장된다. 이때 중간에 데이터를 추가하거나 삭제할 경우에는 인덱스가 한 칸씩 뒤로 밀리거나 당겨진다.
대신! 랜덤엑세스에 유리하다. 인덱스를 가지로 있어서 조회할 때 한 번에 접근이 가능하기 때문에 대용량 데이터를 한 번에 가져와서 여러번 참조해 사용할 때 최상의 성능을 내는 객체다. (+크기 조절이 마음대로..)
Collections.synchronizedList, Collections.synchronizedMap, Collections.synchronizedCollection 등으로 동기화처리가 되는 컬렉션 생성하면 멀티쓰레드환경에서 쓸 수 있다.
그러나 ~를 사용하는게 더 낫다
linkedlist
ArrayList나 Vector와 사용 방법은 동일하다. 하지만 구조는 다르게 구성되어 있다. 위의 컬렉션들은 인덱스로 데이터를 관리하지만 LinkedList는 인접한 곳을 링크하여 체인처럼 관리한다. LinkedList는 중간의 데이터를 삭제할 때 인접한 곳의 링크만을 변경하면 되기 때문에 중간에 데이터를 추가/삭제하는 경우 처리 속도가 빠르다.
추가/삭제가 빈번하게 일어나는 대용량 데이터 처리가 필요할 때 사용하면 성능이 좋다.
대신 랜덤엑세스를 지원하지 않는다. 어디에 어떤 데이터가 있는지는 첫 노드부터 정보를 타고가면서 찾아야 하므로 검색에 있어서 성능이 좋지 않다.
스택, 큐, 양방향 큐등을 만들 때 사용한다.
vector
ArrayList와 동일한 구조를 갖는다. 스레드 동기화 synchronizaion가 되어 있어서
복수의 스레드가 동기에 vector에 접근해서 객채를 추가, 삭제하더라도 thread safe하다.
따라서 단일 스레드만 사용하는 애플리케이션을 만들때는 ArrayList가 성능이 더 좋다.
set 개념과 종류 (hashset, treeset, linkedhashset, sortedset)
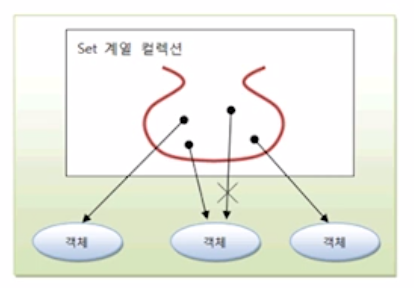
집합의 개념
따라서 순서의 개념이 없으므로 저장 순서를 유지하지 않는 형태로 구현되어있다.
객체를 중복해서 저장할 수 없다.
null도 저장할 수 있는데, 중복해서 저장할 수 없기는 마찬가지(즉 하나의 null만 저장할 수 있다.)
Set은 ArrayList처럼 인덱스가 따로 존재하지 않아 iterator(반복자)를 사용해야한다.
LinkedList도 순서는 있지만 인덱스가 없으므로 iterator를 사용해야 함
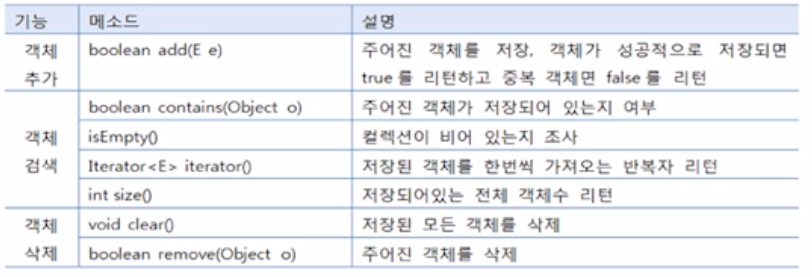
HashSet : 빠른 접근속도를 가지고 있음 단, 순서를 알 수 없음
LinkedHashSet : 추가된 순서대로 접근 가능
map 개념과 종류 (hashmap, treemap, linkedhashmap)
키와 값으로 구성된 Map.Entry 객체를 저장하는 구조
키와 값은 모두 객체
키는 중복 될 수 없지만 값은 중복 저장 가능


keySet() 메소드를 알면 Map컬렉션과 Set컬렉션의 차이점이 무엇인지 알게 되면서 이해에 도움된다.
map에서의 동등성

HashMap : 파이썬의 딕셔너리, 중복X, 순서X, null허용
내부적으로는 배열로 이루어져 있어서 랜덤엑세스에 유리
HashTable : 동기화 지원(HashMap보다 느림), null 불가
LinkedHashMap
Properties :

검색 기능을 강화시킨 컬렉션
내부적으로 이진탐색트리로 구현했기 때문에 검색속도 향상
(스무고개방식, 검색범위를 매회 절반씩 줄여서 검색, 시간복잡도 O(h))
정렬방법을 지정할 수 있음
TreeSet:

TreeMap

정렬된 순서대로 저장되어 검색은 빠르지만, 요소 추가/삭제시 성능이 좋지 않음
멀티스레드환경에서 thread safe하면서도, 퍼포먼스 저하없이 병렬적으로 작업을 처리하도록 하고 싶으면
java.util.concurrent 패키지의
ConcurrentHashMap, ConcurrentLinkedQueue를 사용하면된다.
'Junior 사내스터디' 카테고리의 다른 글
| Collect모듈과 Serving 스터디 중 언급 (0) | 2019.11.27 |
|---|---|
| 카프카에러와 git config --global core.autocrlf false (0) | 2019.11.14 |
| git과 svn의 차이, rebase와 merge의 차이 (0) | 2019.11.13 |
| 스프링부트에서 JdbcTemplate를 직접 사용하여 RestAPI구현하기 (0) | 2019.11.13 |
| DBMS에서 데이버베이스란 용어와 스키마라는 용어 (0) | 2019.11.08 |

댓글